




Introduction
Real-time data processing has become a crucial aspect of modern business operations as companies strive to provide instantaneous, interactive experiences to their customers. With the increasing use of microservices and event-driven systems, there is a growing demand for real-time capabilities that can support these distributed applications. To meet this need, large-scale data processing technologies have emerged that can analyze, process, and transform data streams in real-time.
With this, continuous data streams or clusters can be queried, processed, used to run machine learning functions, and conditions can be detected quickly, as soon as data is received. We have a lot of stream processing technologies available, but this article focuses on two of the most popular:
Apache Flink - is an open-source framework which is used to process large-scale data streams and deliver real-time analytical insights.
Spark - is a high-speed, open-source cluster computing framework that is designed for processing massive amounts of data.
In this article, we provide an introduction to two of the most popular stream processing frameworks in the industry - Apache Flink and Apache Spark. The article provides an overview of their features, pros and cons, and use cases.
Apache Spark
Apache Spark is a popular open-source framework which is used as an analytics engine for big data and machine learning. It was developed with the aim to overcome the limitations of the MapReduce algorithm, which is a first-generation distributed data processing system.
MapReduce processes parallelizable data and performs computation on a horizontally scalable infrastructure. However, as a distributed system, MapReduce has it is own limitations which are:
MapReduce was developed specifically for batch processing on huge volumes of data, which makes it unsuitable for real-time data processing scenarios.
Data processing in MapReduce is slow due to the linear data flow infrastructure which consists of programs that read input data from a disk, process it and store it on the disk again.
Apache Spark was designed to overcome these limitations by introducing a more flexible and efficient data processing engine. It supports in-memory data processing, allowing for faster access to data and more efficient processing. Additionally, Spark has a more versatile data processing model that enables it to handle a variety of data sources, including structured, semi-structured, and unstructured data.
Spark framework partitions in-memory data in a logical manner across multiple machines and refers to these partitions as Resilient Distributed Datasets (RDDs) which is a collection of objects that are cached in memory, and reused in multiple Spark operations. These RDDs act as an abstraction layer, facilitating the management of logically distributed data.
Spark simplifies the data processing pipeline by reading data into memory, performing operations, and writing results back in a single step, leading to faster execution. This streamlined process greatly reduces latency, making Spark several times faster than MapReduce, particularly for machine learning and interactive analytics applications.
When using Spark, the user submits an application through the spark-submit command. This command invokes the main() method specified by the user and launches the driver program. The driver program requests resources from the cluster manager to launch executors.
The cluster manager then launches the executors on behalf of the driver program. The driver program runs with the help of the user application and sends work to the executors in the form of tasks based on the actions and transformations on RDDs.
The executors process the tasks and send the results back to the driver through the cluster manager. This architecture allows for efficient distributed processing of large-scale data sets in a fault-tolerant manner.
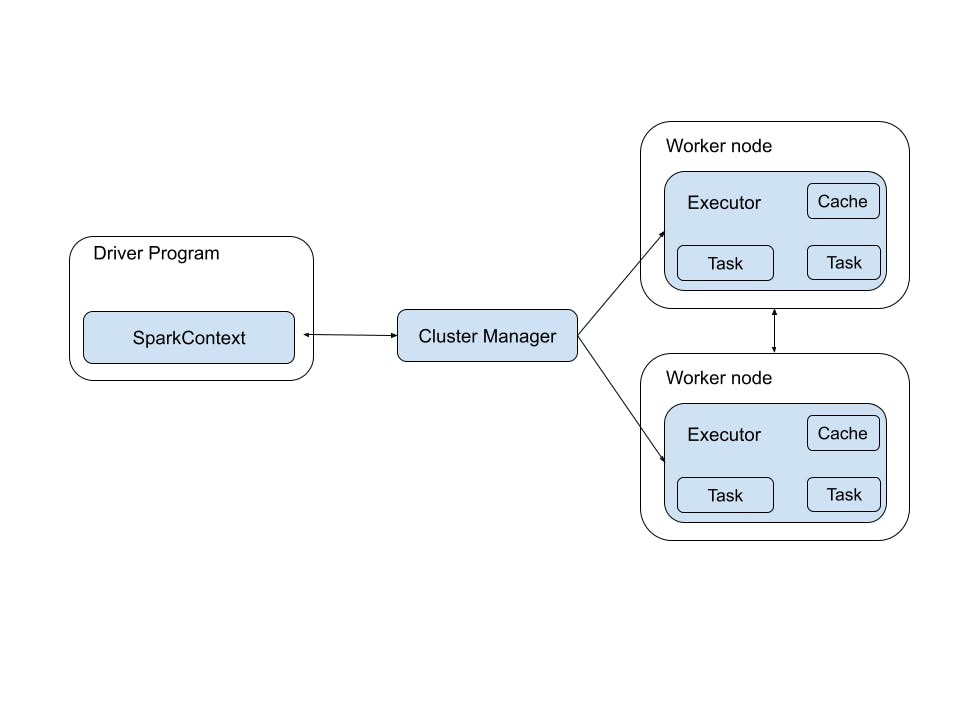
The Apache Spark framework is composed of multiple components such as:
Spark Core - It is the foundation for the platform
Spark Streaming - Used for real-time analytics
Spark MLlib - Designed for machine learning
Spark SQL - Used for interactive querying
Spark GraphX - Used for graph processing
Spark Streaming is considered to be one of the most critical components, as it provides support for real-time data streams generated from a diverse range of sources, including Apache Kafka, Apache Flume, Twitter, and Amazon Kinesis, among others.

Benefits of Spark
Spark's in-memory caching and optimized query execution provide a high-speed analytics engine capable of running complex queries against vast amounts of data in real-time.
Spark's versatile design enables it to support multiple workloads, ranging from interactive queries and real-time analytics to machine learning and graph processing. Its unified platform can seamlessly integrate and execute various workloads within a single application, providing a comprehensive solution for big data processing.
Spark supports multiple programming languages, including Scala, Java, Python, R, and C#, making it accessible to a wide range of developers.
Spark is designed to be fault-tolerant, meaning it can recover from hardware and software failures without losing any data or disrupting the application.
Drawbacks of Spark
High memory consumption - Spark requires a lot of memory, which can make it expensive to run on smaller machines or in memory-constrained environments.
No native stream processing - Spark does not have built-in support for stream processing, requiring developers to use third-party tools or libraries to handle streaming data.
Time windowing only - Spark only supports time-based windowing, which can be a limitation for use cases that require event-based processing.
HDFS as the only state backend - Spark only supports Hadoop Distributed File System (HDFS) as a state backend, which limits its compatibility with other storage systems.
Apache Spark use cases
Spark is a highly versatile distributed processing system that has become a popular choice for big data workloads across a range of industries. Its versatility enables it to be employed across a variety of use cases to detect patterns and provide real-time insights.
Here are some of the use cases:
Healthcare - Spark is leveraged to create a holistic approach to patient care, by providing front-line healthcare workers with access to patient data during each interaction. Additionally, Spark can be employed to predict and suggest optimal treatment options for patients.
Banking and finance - Spark finds extensive use in the banking sector for predicting customer churn and suggesting new financial products. It is also employed in investment banking to analyze stock prices and forecast future trends.
Network security - Utilizing various components of the Spark stack, security providers can conduct real-time inspections of data packets for traces of malicious activity.
Apache Flink
Apache Flink is an open-source distributed processing engine which is used for stateful computation over unbounded and bounded data streams.
Apache Flink facilitates the processing of vast quantities of streaming data from diverse sources, scaling horizontally across numerous nodes in a distributed fashion, and pushing the generated streams to downstream services or applications such as Apache Kafka, databases, and Elastic search.
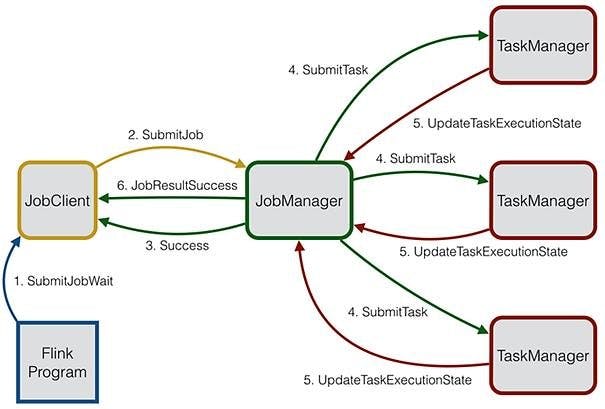
Apache Flink operates in three main components: Task Manager, Job Client, and Job Manager. When a job is submitted to Flink, the Job Client sends it to the Job Manager, which is responsible for coordinating and managing the resources required for executing the job across different Task Managers.
Task Managers, which are the worker nodes, perform the actual computations on the data and report their progress to the Job Manager. Flink's master-slave architecture means that the Job Manager acts as the master node while Task Managers are the slave nodes. At the beginning of the distributed work, the Task Managers send a registration message to the Job Manager and receive an acknowledgement in response.
The Job Manager maintains information about the resources available to each Task Manager and uses this data to assign resources to the different tasks required for executing the job. This distributed architecture enables Flink to process massive streaming data from various sources in a scalable and fault-tolerant manner before pushing the results to other applications or services such as Apache Kafka, DBs, and Elastic search.
Flink solves the problem of processing large volumes of streaming data in real-time by providing a scalable and fault-tolerant platform. It offers features like event-time processing, state management, and windowing that make it well-suited for a wide range of use cases, including:
Supply chain optimization - Flink can optimize supply chain operations by analyzing streaming data from various sources such as sensors, logistics, and inventory management systems.
Clickstream analysis - Flink can analyze clickstream data in real-time to provide insights into customer behaviour and preferences.
Fraud detection - Apache Flink can detect fraudulent transactions and activities in real-time by analyzing large volumes of streaming data.
Flink is also designed to handle batch processing and can run both batch and stream processing jobs in the same runtime environment. This makes it a versatile platform that can support a wide range of data processing workflows.
When compared to Apache Spark, Apache Flink brings some advantages to real-time stream processing, such as:
Native stream processing: While Spark was designed primarily for batch processing, Flink was designed from the ground up with stream processing in mind. This makes Flink a better choice for handling real-time data streams.
Stateful stream processing: Flink provides support for stateful stream processing, which means it can maintain and update the state as new data arrives in a stream. This is particularly useful for use cases such as fraud detection, where it's important to keep track of ongoing activity.
Low-latency processing: Flink can achieve lower latency than Spark due to its pipelined execution model, which processes data in small batches as it arrives, instead of waiting for a full batch to be collected.
Dynamic scaling: Flink can scale both up and down dynamically based on the incoming data stream, which makes it more efficient and cost-effective than Spark in some scenarios.
Conclusion
In conclusion, we have learned that Apache Flink and Apache Spark are two widely used big data processing systems. While Spark has several benefits, including supporting multiple languages and having advanced analysis capabilities, it also has some drawbacks, such as high memory consumption and no native stream processing. On the other hand, Apache Flink offers a better solution for real-time stream processing, with its ability to handle high data volumes, low latency, and better fault tolerance.