

Web scraping: Using Scrapy in Python to Scrape Amazon Website
In this tutorial, we are going to extract data from Amazon website


Introduction
Web scraping is simply the process of extracting data from a website.
Web scraping has been ruled legal (And thus it is not stealing data), and python bots are allowed to crawl websites to fetch data from them. However, there are websites with strict policies that prevent bots from scraping their hard-earned data, an example of which is LinkedIn.
But how do we scrape data from the web? In this article, we would focus solely on a tool called Scrapy that allows us to scrape and fetch data from the web.
Let’s dive right in!!
Setting up the environment
First, we will be using python and you should make sure that you have python installed on your system and also the Scrapy package.
To check if python is installed, run the following command:
# Checking the version of python
python3 --version
Output:

To install Scrapy and its dependencies from PyPI, run the following command:
# Installing Scrapy
pip install Scrapy
Setting up a Scraper
Now, we will set up a Scraper by creating a file and naming it amazon_laptops.py with this content:
import scrapy
class AmazonSpider(scrapy.Spider):
name = 'scrape laptops'
start_urls= ["https://www.amazon.com/s?k=laptop"]
headers = {
"User-Agent": "Mozilla/5.0"
}
def response(self, response):
pass
Inside the class, we have:
name: Name of the scraper
start_urls: List of URLs from which the scraper begins
headers: We add a special header “User-Agent” so that Amazon does not block us. Without it, we will get a 503 error. You can add other headers according to your liking.
parse: This is the function that does the actual parsing. This is our next part.
Inspecting the web page
Inspecting is simply looking at web page source code. From this, we will extract elements using selectors. There are two main selectors in Scrapy, CSS and XPath.
To inspect a page, right-click on an element on the web page then click inspect. On Chrome, you can press ctrl+shift+c and then select the element.
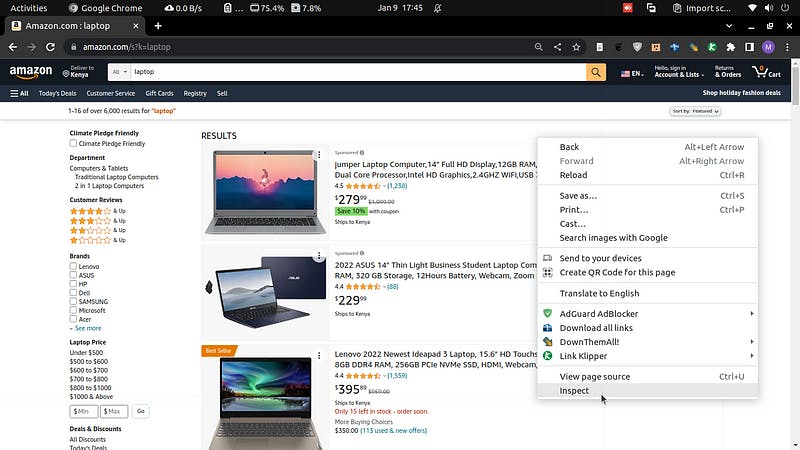
Selecting elements
For this tutorial, we will be using XPath but you are free to use CSS.
We can inspect the title of any laptop on our Amazon webpage.


Right-click and copy the XPath.

We get:
//*[@id="search"]/div[1]/div[1]/div/span[1]/div[1]/div[3]/div/div/div/div/div/div/div/div[2]/div/div/div[1]/h2/a/span/text()
You can do this for any other data you need. For example:
stars:
//*[@id="search"]/div[1]/div[1]/div/span[1]/div[1]/div[5]/div/div/div/div/div/div/div/div[2]/div/div/div[2]/div/span[1]/span[1]/text()
reviewers:
//*[@id="search"]/div[1]/div[1]/div/span[1]/div[1]/div[5]/div/div/div/div/div/div/div/div[2]/div/div/div[2]/div/span[2]/a/span/text()
Iterating for every laptop
So far, we have shown for one laptop, but we need to do this for every laptop. To do that, you notice that the divs for the laptops have the same class. Using XPath, we can extract all divs that have this class.
These are the steps to iterate:
Get the parent of all laptop cards. To do that, inspect any laptop.
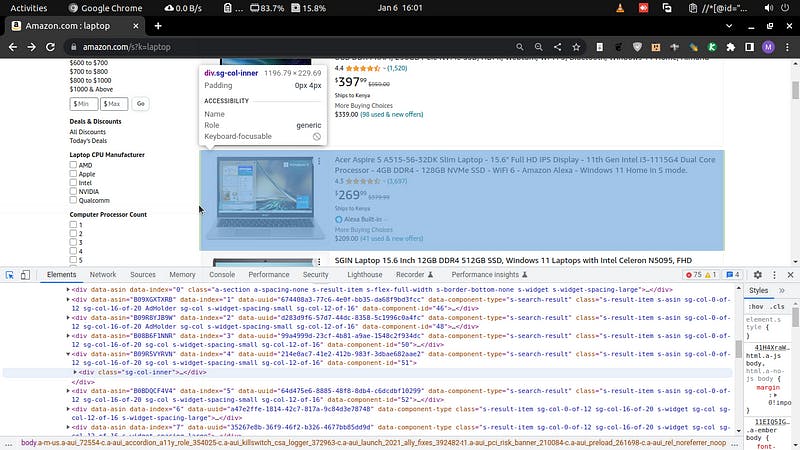
Then collapse its
divuntil the highest level with similardivs. Then get the XPath of the parent div of all those divs.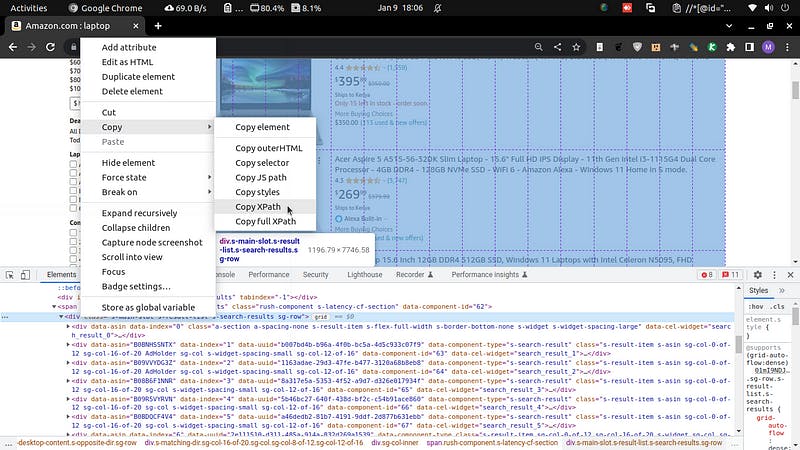
You will get:
'//*[@id="search"]/div[1]/div[1]/div/span[1]/div[1]Then get all the divs by specifying the class in the selector, and copy the class of each laptop div:
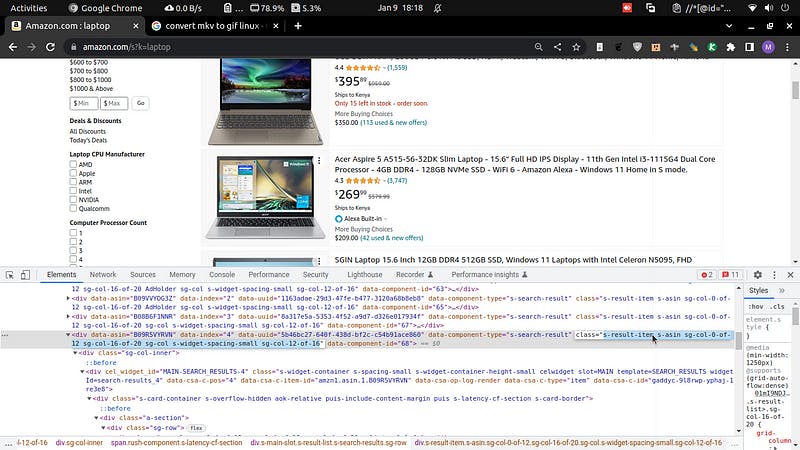
Now, our new selector will be:
'//*[@id="search"]/div[1]/div[1]/div/span[1]/div[1]/div[@class="sg-col-20-of-24 s-result-item s-asin sg-col-0-of-12 sg-col-16-of-20 sg-col s-widget-spacing-small sg-col-12-of-16"]') '//*[@id="search"]/div[1]/div[1]/div/span[1]/div[1]/div[5]In the first one, we have our new selector using class specifier, while in the second is a comparison of only one div, the fifth div.
Putting it all together
Now, our new code will look like this after putting everything together:
import scrapy
import json
class AmazonSpider(scrapy.Spider):
start_urls= ["https://www.amazon.com/s?k=laptop"]
headers = {
"User-Agent": "Mozilla/5.0"
}
name = 'scrape laptops'
data = list()
def parse(self, response):
divs = response.xpath('//*[@id="search"]/div[1]/div[1]/div/span[1]/div[1]/div[@class="sg-col-20-of-24 s-result-item s-asin sg-col-0-of-12 sg-col-16-of-20 sg-col s-widget-spacing-small sg-col-12-of-16"]')
for div in divs:
title = div.xpath('div/div/div/div/div/div[2]/div/div/div[1]/h2/a/span/text()').extract()[0]
stars = div.xpath('div/div/div/div/div/div[2]/div/div/div[2]/div/span/span/text()').extract()
reviewers = div.xpath('div/div/div/div/div/div[2]/div/div/div[2]/div/span[2]/a/span/text()').extract()
# I included other information below.
price = div.xpath('div/div/div/div/div/div[2]/div/div/div[3]/div[1]/div/div[1]/div/a/span[1]/span[1]/text()').extract()
# link to the laptop
link = div.xpath('div/div/div/div/div/div[2]/div/div/div/h2/a/@href').extract()[0]
link = "https://www.amazon.com" + link
info = {
"title": title,
"stars": stars,
"reviewers": reviewers,
"price": price,
"link": link
}
self.data.append(info)
with open('amazon_laptops.json', 'w') as f:
json.dump(obj=self.data, fp=f)
if __name__ == "__main__":
process = CrawlerProcess()
process.crawl(AmazonSpider)
process.start()
Running the code:
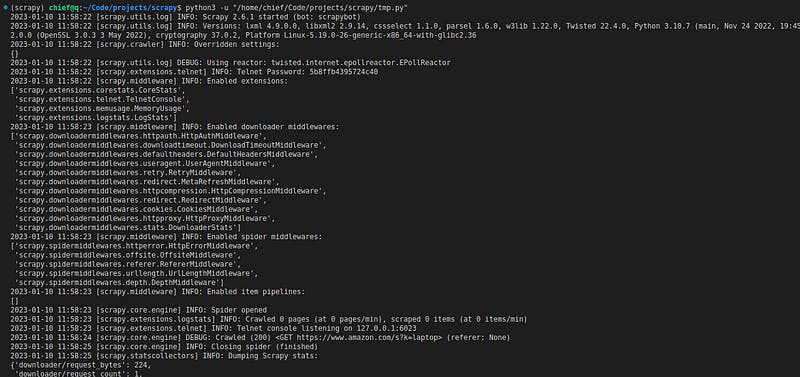
Huraaay!!
We have successfully scraped the Amazon website and now we have the data on the laptops being sold on the website.
Here is the sample output of the data:

Conclusion
In this tutorial, we have used Scrapy and python. We have seen how to inspect a page, how to select elements using XPath, and how to extract the data from Scrapy selectors. We have stored the data in a JSON file.
Please follow me for more exciting content!