


Apache Flink 101: Understanding the Architecture
The rise of real-time and batch processing


Time = value
Introduction
Data is generated from many sources, including financial transactions, location-tracking feeds, measurements from Internet of Things (IoT) devices, and web user activity. Formerly, batch processing was used to manage these continuous data streams after they had been saved as datasets.
However, there is a demand to process data in real-time hence Time = Value. Businesses demand real-time computation so as to make informed decisions in real time. Because of this, companies are switching to stream processing software. Apache Flink is the most popular and widely adopted streaming processing framework that is used to process huge volumes of data at a lightning-fast speed.
In this article, we'll learn about the important aspects of Apache Flink's architecture and how it works.
Kappa Architecture
To understand how Apache Flink works, it is prudent that we begin with understanding what is Kappa architecture.
Kappa architecture is a data processing architecture mainly built for processing streaming data. It is a simplification of Lambda architecture which is built to process data in batches.
In Kappa architecture, batch processing is a special case of stream processing hence it is able to perform both batch and real-time processing, especially for analytics, with a single technology stack.
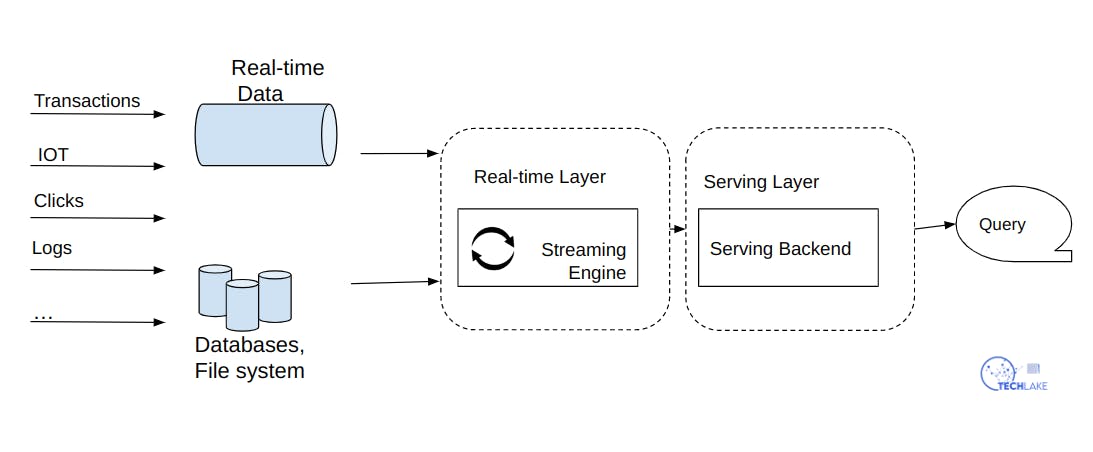
It is built on a streaming architecture where incoming data streams are initially stored in a message engine like Apache Kafka. The data will then be read by a stream processing engine, formatted for analysis, and stored in an analytics database for end users to query.
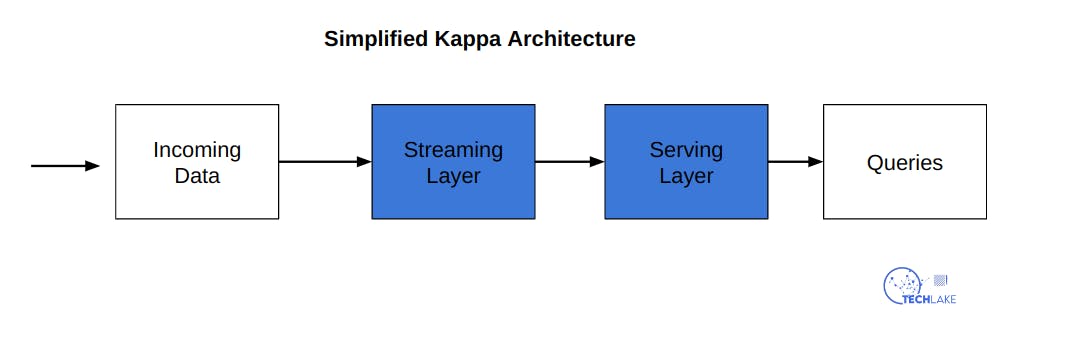
Apache Flink is built on Kappa architecture hence it excels at processing unbounded and bounded data sets.
Through precise control of time and state, Flink's runtime is enabled to run any kind of application on unbounded streams. For bounded streams, they are internally processed by algorithms and data structures that are specifically designed for fixed-sized data sets, yielding excellent performance.
Apache Flink job execution architecture
Apache Flink has mainly three distributed components, i.e. Task Manager, Job Client and Job Manager. The client submits jobs to the Job Manager which in turn orchestrates jobs on different managers and also manages the resources. Task managers are the actual worker nodes doing the computations on the data and updating the job manager about their progress.
It is true that Apache Flink uses a master-slave architecture. Whereas task managers are workers or slave nodes, a job manager serves as the master in this system. Task managers give the Job manager a register message at the beginning, and they receive an acknowledgement of the registration. The condition of the distributed work that needs to be completed as well as information about various resources on task managers are maintained by the job manager. The data is used to assign resources to various tasks.

Program
A Flink program comprises multiple tasks. It is basically a piece of code which you run on the Flink cluster.
Job Client
The client is used for communicating with the Job manager. It takes the program (the code) and then passes it to the Job Manager. It is also used in querying the status of different running jobs.
Job Manager
A job manager is used to perform the following functions:
It communicates with the Task Manager using the Actor system.
The job manager provides a scheduler which is responsible for scheduling tasks.
It is used to transform the JobGraph from the Client into an ExecutionGraph for event execution.
It provides a checkpoint coordinator to adjust the checkpointing of each task, including checkpointing start and end times.
It provides the recovery metadata used to read data from metadata while recovering a fault.
Task Manager
The task manager does the work of executing all the tasks that have been assigned by the Job manager. It is also responsible for sending the status to the job manager. The execution of tasks begins after the Job Manager applies the resources.
The task manager is divided into various task slots and each task runs within a task slot - the task slot is the smallest unit for resource scheduling.
These are the components of a Task Manager:
An Actor System which is used to implement network communication.
Network Manager which is used to manage networks.
Memory and I/O manager used to manage the memory I/O
Conclusion
In this article, we have looked at the architecture of Apache Flink beginning with Kappa architecture. We have discussed the various components that comprise Apache Flink and how job execution works.